Any hardware of software component that stores data so that future requests can be served faster. The data stored could be the result of a computation or data stored elsewhere in a slower to access storage.
If the results of a call is returned from the cache, its called a cache hit. If the result doesn't exist in the cache and the application needs to reach out to the authority, its called a cache miss.
An authoritative data store is sort of the System of Record (SoR) that always contains the latest state for that resource or entity. On the other hand, a cache data store could be a subset, the full set or joins of multiple data sources that could be used to serve the same (or augmented) data faster.
As such, a cached data store will never be an authoritative data store and should not be treated as such.
Comes from the principle of locality, which is the tendency of a processor to access the same set of memory locations repetively over a short period of time. In computer applications, this could be true as well where a subset of the data is accessed much more than others and thus, makes sense to be cached. Such access patterns could exhibit:
Apache Hadoop is great example of how this can be realized in a distributed system. Taking its example:
Another non-product specific example with distributed systems could be:
This is a huge point of discussion in any system design interview. Too many caches across different layers of the stack could lead to data inconsistencies if one (or more) of those caches have stale data. Too few (or no cache) could mean higher latencies and lower throughput. So where to put in the cache?
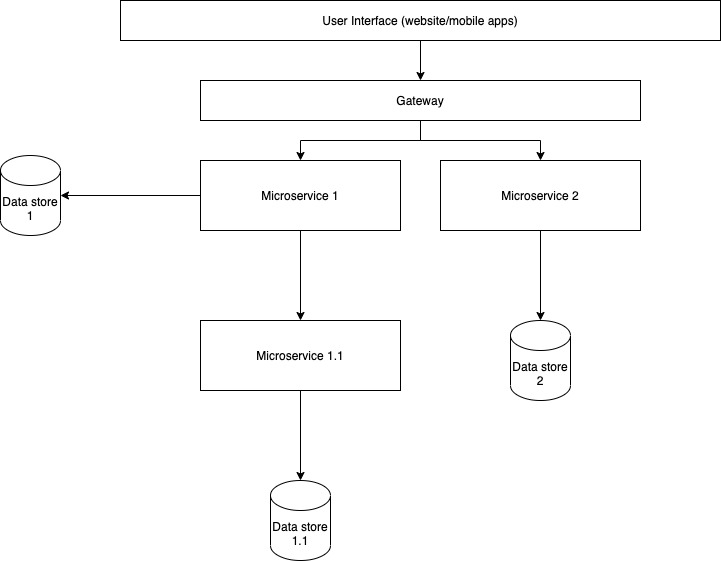
Lets take a "typical web" of micro-services:
Assuming we want better latencies from Microservice 1, there are a few opportunities to cache here:
Now lets say we want the best latencies, so we choose 1.3 and 2.1,
Now imagine this happening across tens of microservices owned by different teams.
The purpose of this exercise is to illustrate caches are not a silver bullet solution to speed things up and often "where to put a cache" is not easily answered. The best path forward is to profile and benchmark and identify the "slow" points in the call stack and evaluate if it makes sense to add a cache there. Other considerations are:
Caches at the application level, the caches in the previous section are example of those. Application level caches could be of two types:
Typically used to serve static content (CSS, JS, etc) by locally caching the content on the edge, preferably in a geography closest to the user. Example: AWS Cloudfront.
A CDN usually follows one of these two delivery methods:
Its a tradeoff to decide which one to use when. For instance, if there are millions of static content that almost never changes, push might work better because we wouldnt want to expire and re-populated all these content periodically. However, if the site is seldom visited from a geography, it wouldnt make sense to push the content to that geography. A pull model might work better in that case.
Best for read-only data that can be predicted to be requested for, the cache is populated beforehand.
Best for data that cannot be predicted to be requested for, the cache is populated when there is a demand for the block of data.
There are two concepts for removing cache entries:
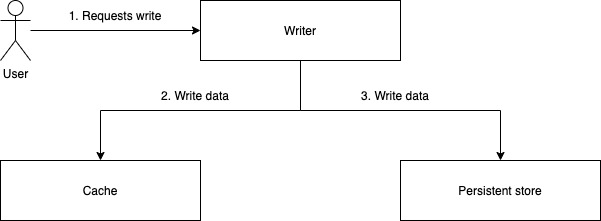
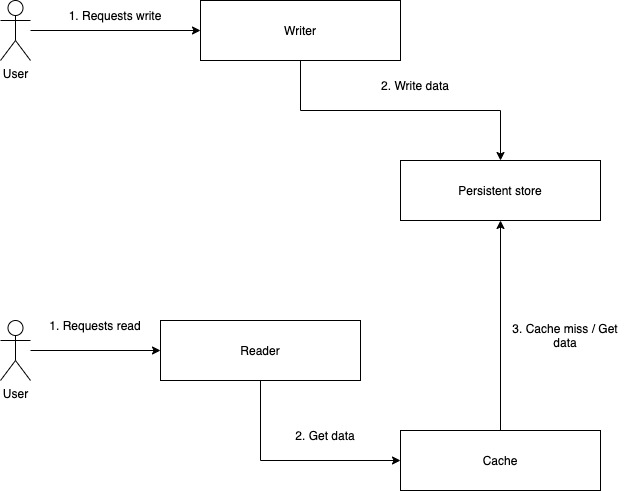
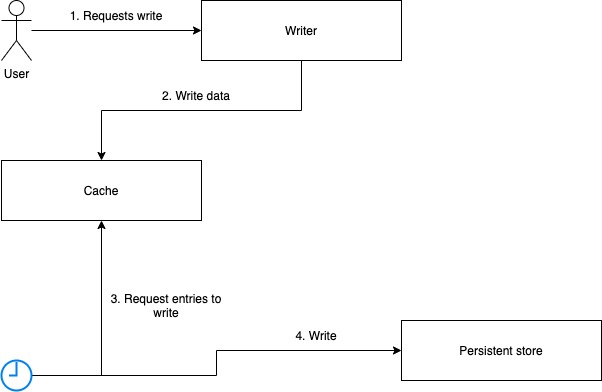
It depends on the application needs. The following matrix gives an idea on how to map to a strategy based on the application's needs.
| Strategy | Data loss probability | Write Latency | Read Latency |
|---|---|---|---|
| Write-through | Low | High | Low |
| Write-around | Low | Low | High |
| Write-back | High | Low | Low |
| Policy | Description |
|---|---|
| First In First Out (FIFO) | Evicts first accessed block |
| List In First Out (LIFO) | Evicts the last accessed block |
| Least Recently Used (LRU) | Evicts the block that was used the least recent, aka, among the block the one that was used first |
| Time Aware Least Recently Used (TLRU) | Evicts blocks with small Time To Use (TTU) and less recently used |
| Most Recently Used (MRU) | Opposite of LRU |
| Least Frequently Used (LFU) | Evicts the block used the least frequently |
| Least Frequently Recently Used (LFRU) | Has a privileged partition with most used blocks. Evicts unprivileged blocks and pushes popular blocks to privileged partition |
| Random Replacement (RR) | Randomly evicts a block |